Meteorológiai társalgó
Hasznos linkek (és egy infó)
>> Sat24 műholdképek>> Sat24 Magyarország mozgó műholdkép
>> Magyarországi radarképek archívuma
>>Tippelek az előrejelzési verseny aktuális fordulójában!
>>Rádiószondás felszállások élő követése!
>>Észlelés (közeli villámlás, jégeső, viharos szél, villámárvíz, szupercella, tuba, porördög, tornádó, víztölcsér, viharkár) beküldése a szupercella.hu-nak!
----------
Képek beillesztése esetén kérjük azokat megvágni, reklámok, mobilok fejléce, stb. csak feleslegesen foglalja a helyet és áttekinthetetlenné teszi az oldalt - a vágatlan képek ezért törlésre kerülnek.
Fotózáskor kérjük a mobilt fektetve használni, egy keskeny de magas kép egyrészt szintén sok helyet foglal, másrészt a kép sem túl élvezetes.
Köszönjük az együttműködést és a megértést.

A homogenizált adatosorokra gondolom ott van szükség, ahol ezeket egy másik rendszer inputjaként adod be. Például egy éghajlatváltozást vizsgáló algoritmus bemenetként minél hosszabb változatlan adatsort vár. Nem teheted meg, hogy beadod a homogenizálatlan adatsort, hiszen nem tudod beadni az egyes mérések szakaszait, hogy 1901-1950 belváros, 1951-1990 külváros, mert nem teszi lehetõvé az adott program/algoritmus stb. Ha pedig lehetõvé teszi, akkor meg õ maga homogenizál úgyis belül, és akkor már jobb ha Te csinálod több ésszel.
Sokszor ugyanis nem elég a t - (t-1) vizsgálat, mert akkor nem tudod összevetni a t(Ásotthalom) és t(Szeged) értékeket, vagy a t(globális) és t(magyar) értékeket stb. stb. Ezért én arra tippelnék, hogy megállja a helyét a rendes és a homogenizált adatsor is, függõen attól, hogy mire használjuk.
Persze ha az adatsor maga a végeredmény akar lenni, egyedül, magában, akkor megfelelõ leírás, magyarázat mellett egyetértek azzal, amit mondasz, nem kell a homogenizáció. Azt is tudja szerintem mindenki, hogy hamis adatok állnak elõ, mégis abban a hiszemben teszik, hogy a kapott adatsor mégis pontosabb, mint homogenizáció elõtt (az adott feladatot tekintve).
Aztán lehet rosszul gondolom.
Sokszor ugyanis nem elég a t - (t-1) vizsgálat, mert akkor nem tudod összevetni a t(Ásotthalom) és t(Szeged) értékeket, vagy a t(globális) és t(magyar) értékeket stb. stb. Ezért én arra tippelnék, hogy megállja a helyét a rendes és a homogenizált adatsor is, függõen attól, hogy mire használjuk.
Persze ha az adatsor maga a végeredmény akar lenni, egyedül, magában, akkor megfelelõ leírás, magyarázat mellett egyetértek azzal, amit mondasz, nem kell a homogenizáció. Azt is tudja szerintem mindenki, hogy hamis adatok állnak elõ, mégis abban a hiszemben teszik, hogy a kapott adatsor mégis pontosabb, mint homogenizáció elõtt (az adott feladatot tekintve).
Aztán lehet rosszul gondolom.
Utolsó észlelés
Térképek
Radar
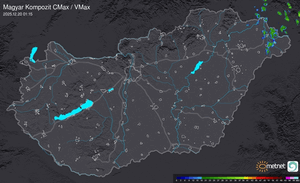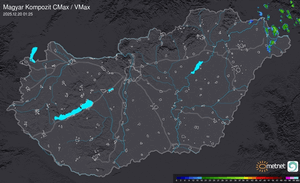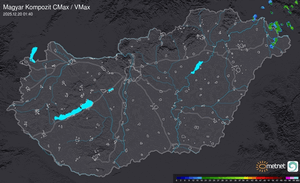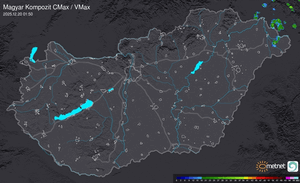
Aktuális hõmérséklet
Aktuális szél
Utolsó kép

Érdekességek | 2026-03-27 16:50
Szabályzat